Version v0.1 of the SEmantic Large-Scale Multimodal Acquisitions dataset, or SELMA Dataset for short, has just been released.
The paper preprint is available at ArXiv: 2204:09788.
The dataset was realized by the SCANLAB and the LTTM research groups at the University of Padova.
On this page, we will overview the main features of the dataset itself.

This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
Modalities (Sensors):
One of the major focuses of this dataset is the multimodal aspect of the data samples provided. In particular, we rendered 30’909 unique scenes in 27 environmental conditions, capturing the scene with the following sensors:
- 7 Color Cameras:
- 3 frontal cameras (FRONT_LEFT, FRONT, FRONT_RIGHT), rectified and separated by 25cm. Can be used as 3 distinct stereo setups with baselines: 25cm (FL-F), 50cm (FL-FR) and 25cm (F-FR).
- 1 desk camera (DESK).
- 3 ring cameras (LEFT, RIGHT, BACK), facing in the remaining cardinal directions, providing a 360° view.
- 7 Depth Cameras, placed in coincidence with the color cameras to provide 2.5D information. The depth is provided in CARLA format, to get the depth in meters one must load the PNG file as an RGB image and perform the following computation: d = 1000*(R + G*256 + B*256*256)/(256*256*256 - 1).
- 3 LiDARS (64 channels, ~100k points per scan, provided in binary PLY format):
- 1 top LiDARs (TOP), with a 360° view of the scene.
- 2 front-lateral LiDARs placed on the headlights with 270° of aperture, overlapping in the front of the ego vehicle. The three LiDAR pointclouds can be merged to achieve higher density in such region.
- 1 Surface Normal Camera (estimated):
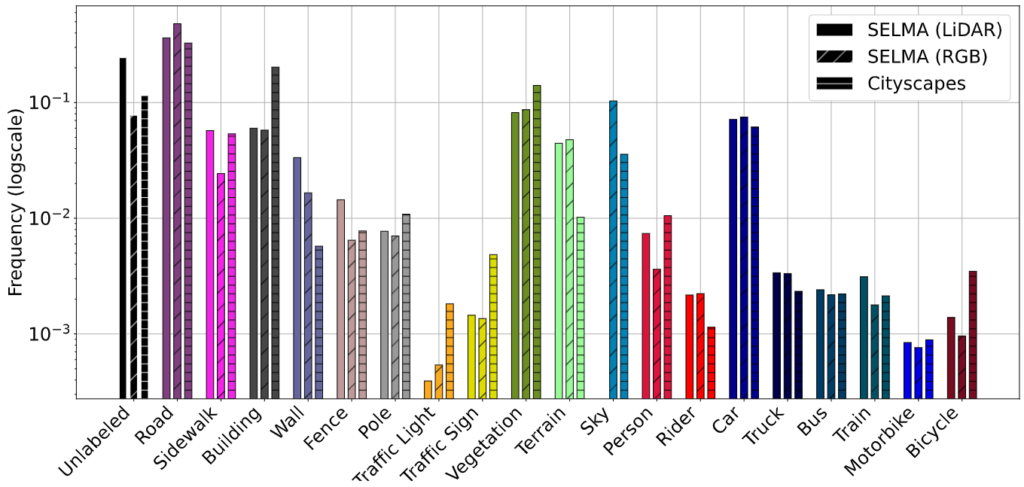
Semantic Classes:
To better align with the common synthetic-to-real segmentation benchmark, Cityscapes, we generated the semantic labels for each sample (both for the cameras and the LiDARs) in a strict superset (36 classes in total) of the classes considered in the benchmark:
| Class Name | Raw ID | Train ID | Cityscapes ID (35 classes) |
Color (RGB) |
|---|---|---|---|---|
| Unlabeled | 0 | -1 | 0 |
■ (000, 000, 000)
|
| Building | 1 | 2 | 11 |
■ (070, 070, 070)
|
| Fence | 2 | 4 | 13 |
■ (190, 153, 153)
|
| Other | 3 | -1 | 0 |
■ (000, 000, 000)
|
| Pole | 5 | 5 | 17 |
■ (153, 153, 153)
|
| Road Line | 6 | 0 | 7 |
■ (110, 190, 160)
|
| Road | 7 | 0 | 7 |
■ (128, 064, 128)
|
| Sidewalk | 8 | 1 | 8 |
■ (244, 035, 232)
|
| Vegetation | 9 | 8 | 21 |
■ (107, 142, 035)
|
| Ego Vehicle | 10 | -1 | 1 |
■ (000, 000, 000)
|
| Wall | 11 | 3 | 12 |
■ (102, 102, 156)
|
| Traffic Sign | 12 | 7 | 20 |
■ (220, 220, 000)
|
| Sky | 13 | 10 | 23 |
■ (070, 130, 180)
|
| Ground | 14 | -1 | 6 |
■ (081, 000, 081)
|
| Bridge | 15 | -1 | 15 |
■ (150, 100, 100)
|
| Rail Track | 16 | -1 | 10 |
■ (230, 150, 140)
|
| Guard Rail | 17 | -1 | 14 |
■ (180, 165, 180)
|
| Traffic Light | 18 | 6 | 19 |
■ (250, 170, 030)
|
| Static | 19 | -1 | 4 |
■ (110, 190, 160)
|
| Dynamic | 20 | -1 | 5 |
■ (111, 074, 000)
|
| Water | 21 | -1 | 36 (extra) |
■ (045, 060, 150)
|
| Terrain | 22 | 9 | 22 |
■ (152, 251, 152)
|
| Person | 40 | 11 | 24 |
■ (220, 020, 060)
|
| Rider | 41 | 12 | 25 |
■ (255, 000, 000)
|
| Car | 100 | 13 | 26 |
■ (000, 000, 142)
|
| Truck | 101 | 14 | 27 |
■ (000, 000, 070)
|
| Bus | 102 | 15 | 28 |
■ (000, 060, 100)
|
| Tram/Train | 103 | 16 | 31 |
■ (000, 080, 100)
|
| Motorcycle | 104 | 17 | 32 |
■ (000, 000, 230)
|
| Bicycle | 105 | 18 | 33 |
■ (119, 011, 032)
|
| Unknown | 255 | -1 | 0 |
■ (000, 000, 000)
|
Dataset Structure
The acquisitions are archived per scene and per sensor. A scene is a combination of a town and an environmental condition (weather and time-of-day). For instance, Town02_Opt_CloudyNoon is the scene acquired in Town02_Opt with a Cloudy sky at Noon. From the website, it is possible to select the data to download by combining different towns and environmental conditions. Furthermore, we offer the possibility to download only a subset of sensor data (e.g., only that acquired by the CAM_LEFT, i.e., the camera on the left side of the vehicle).
| Weather | Clear | Cloudy | Wet | WetCloudy | SoftRain | MidRainy | HardRain | |
| Time-of-day | Noon | Sunset | Night | |||||
| Town | Town01_Opt | Town02_Opt | Town03_Opt | Town04_Opt | Town05_Opt | Town06_Opt | Town07_Opt | Town10HD_Opt |
Download Instructions
1. Navigate to https://scanlab.dei.unipd.it/app/dataset
2. Login or register to access the data. We need you to register to monitor the traffic to/from our server and avoid overloading it. We will only use your e-mail for very limited service communications (new dataset releases, server status).
3. Select the subset of data you want to download using the selection tool available on the dataset page. We suggest starting with the SELMA random split (SELMA rand), that can be downloaded without setting any selection filter.

4. When prompted, download and unzip the archive. The zip contains the downloader toolkit: an executable downloader and a JSON file with the list of files to download.
5. Enable the execution of the downloader for your platform changing the permission accordingly (chmod +x downloader-<yourOS>.sh on Unix systems, double click and accept on Windows).
6. Execute the downloader and.. you’re set! You will find a new “CV” folder in the dataset-downloader-toolkit folder with all the data.
The data will be downloaded in a subfolder structure <SCENE_NAME>/<SENSOR_NAME> where <SCENE_NAME> is obtained as <Town_EnvironmentalCondition>.